Project Title and Overview:
Title:
Auslan Fingerspelling Translation System Using Computer Vision and Deep Learning
Overview:
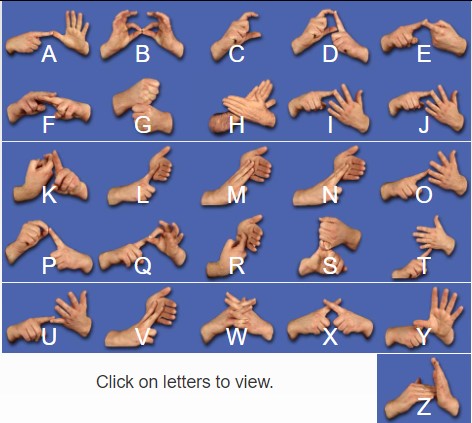
In this project, I developed a system to recognize Auslan (Australian Sign Language) handshapes using computer vision and deep learning techniques. The system converts handshapes representing alphabetic letters (A-Z) into text, facilitating better communication between the deaf and hearing communities.
This system was trained using a custom dataset created with MediaPipe's Holistic model and leveraged LSTM-based deep learning for sequence classification. The project achieved an accuracy of 97.5% on the test set.
Project Objective:
Objective:
The primary goal of this project is to create a real-time recognition system that can identify handshapes corresponding to Auslan letters of the alphabet (A-Z). The system can be extended to recognize full sign language sentences in the future, bridging communication gaps for the deaf community.
Key Use Cases:
Accessibility: Enhance communication for individuals using Auslan.
Education: Assist educators and learners in practicing Auslan.
Public Services: Provide Auslan recognition capabilities in public service settings to improve inclusivity.
Technology Stack:
Languages: Python
Libraries:
- MediaPipe: For real-time hand, face, and pose landmark detection.
- TensorFlow/Keras: For building the deep learning model.
- OpenCV: For image processing and handling webcam input.
- Matplotlib: For visualizing the keypoints and training accuracy/loss charts.
- Scikit-learn for model evaluation metrics and data splitting.
Dataset Collection and Preparation:
Dataset:
Custom dataset created using MediaPipe's Holistic model, capturing 30-frame sequences for each letter (A-Z).
Number of Sequences: 50 sequences per letter
Total Sequences: 26 letters * 50 sequences = 1300 sequences
Sequence Length: 30 frames
The data collection process code briefly to give an idea of how keypoints were captured.
# Data collection code
cap = cv2.VideoCapture(0)
with mp_holistic.Holistic(min_detection_confidence=0.5, min_tracking_confidence=0.5) as holistic:
for action in actions:
for sequence in range(no_sequences):
for frame_num in range(sequence_length):
ret, frame = cap.read()
image, results = mediapipe_detection(frame, holistic)
draw_styled_landmarks(image, results)
keypoints = extract_key_points(results)
npy_path = os.path.join(DATA_PATH, action, str(sequence), str(frame_num))
np.save(npy_path, keypoints)
cap.release()
cv2.destroyAllWindows()
Keypoints Extraction:
Keypoints for the pose, face, left hand, and right hand were extracted from the video frames using MediaPipe.
- Pose: 33 landmarks
- Face: 468 landmarks
- Left and Right Hand: 21 landmarks each
Visualize these keypoints for better understanding. Here’s how you would display keypoints:
def extract_key_points(results):
pose = np.array([[res.x, res.y, res.z, res.visibility] for res in results.pose_landmarks.landmark]
).flatten() if results.pose_landmarks else np.zeros(33*4)
face = np.array([[res.x, res.y, res.z] for res in results.face_landmarks.landmark]
).flatten() if results.face_landmarks else np.zeros(468*3)
left_hand = np.array([[res.x, res.y, res.z] for res in results.left_hand_landmarks.landmark]
).flatten() if results.left_hand_landmarks else np.zeros(21*3)
right_hand = np.array([[res.x, res.y, res.z] for res in results.right_hand_landmarks.landmark]
).flatten() if results.right_hand_landmarks else np.zeros(21*3)
return np.concatenate([pose, face, left_hand, right_hand])
Data Augmentation
To make the model more robust, I applied data augmentation techniques like:
- Noise Addition
- Scaling
- Rotation
# Noise Injection
def add_noise(sequence, noise_level=0.05):
noise = np.random.normal(0, noise_level, sequence.shape)
return sequence + noise
# Scaling
def scale_sequence(sequence, scale_factor=0.1):
scaling = np.random.normal(1.0, scale_factor)
return sequence * scaling
# Rotation
def rotate_sequence(sequence, angle_range=10):
angle = np.random.uniform(-angle_range, angle_range)
theta = np.deg2rad(angle)
cos_theta, sin_theta = np.cos(theta), np.sin(theta)
rotation_matrix = np.array([[cos_theta, -sin_theta], [sin_theta, cos_theta]])
sequence_aug = sequence.copy()
num_frames, num_features = sequence.shape
for t in range(num_frames):
frame = sequence[t]
num_keypoints = int(frame.shape[0] / 3)
for i in range(num_keypoints):
idx = i * 3
x, y = frame[idx], frame[idx+1]
xy = np.array([x, y])
rotated_xy = rotation_matrix.dot(xy)
sequence_aug[t, idx], sequence_aug[t, idx+1] = rotated_xy[0], rotated_xy[1]
return sequence_aug
# Function to randomly augment a sequence
def augment_sequence(sequence):
augmented_sequence = sequence.copy()
if np.random.rand() < 0.5:
augmented_sequence = add_noise(augmented_sequence)
if np.random.rand() < 0.5:
augmented_sequence = scale_sequence(augmented_sequence)
if np.random.rand() < 0.5:
augmented_sequence = rotate_sequence(augmented_sequence)
return augmented_sequence
Augmented Example:
Include a before-and-after visualization of the keypoints to show how augmentation changes the data.
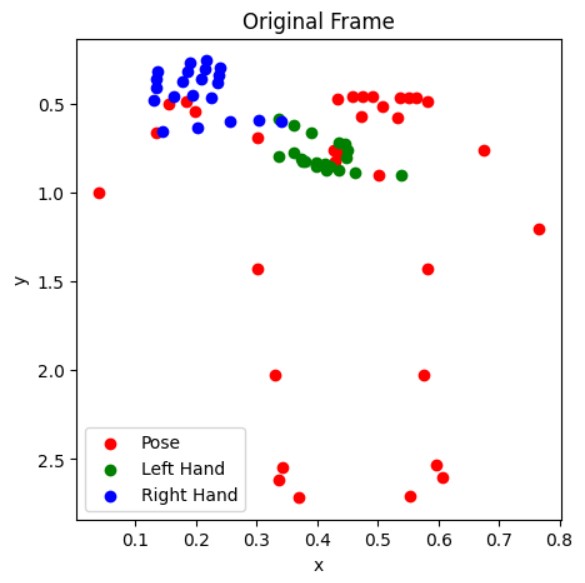
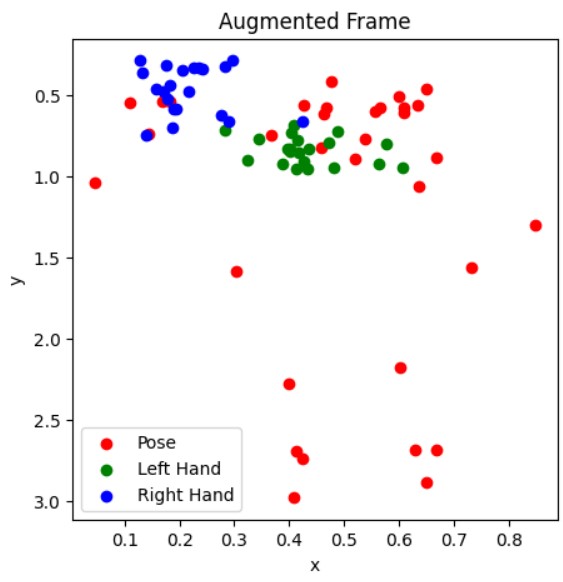
Model Architecture:
The model is based on LSTM networks to handle the temporal nature of the sign language sequences.
# Model architecture code snippet
model = Sequential([
LSTM(64, return_sequences=True, activation='relu', input_shape=(sequence_length, X.shape[2])),
LSTM(128, return_sequences=True, activation='relu'),
LSTM(64, activation='relu'),
Dense(64, activation='relu'),
Dense(len(actions), activation='softmax')
])
Model Summary:
- Input: 30-frame sequences of landmark keypoints.
- Layers:
- Three LSTM layers (64, 128, 64 units respectively).
- Dense layer with softmax output.
- Optimizer: Adam
- Loss Function: Categorical Crossentropy
Training and Evaluation:
The model was trained using 30 epochs, with data split into training and test sets (80-20). Follwoing the training accuracy and loss charts to visualize model performance.
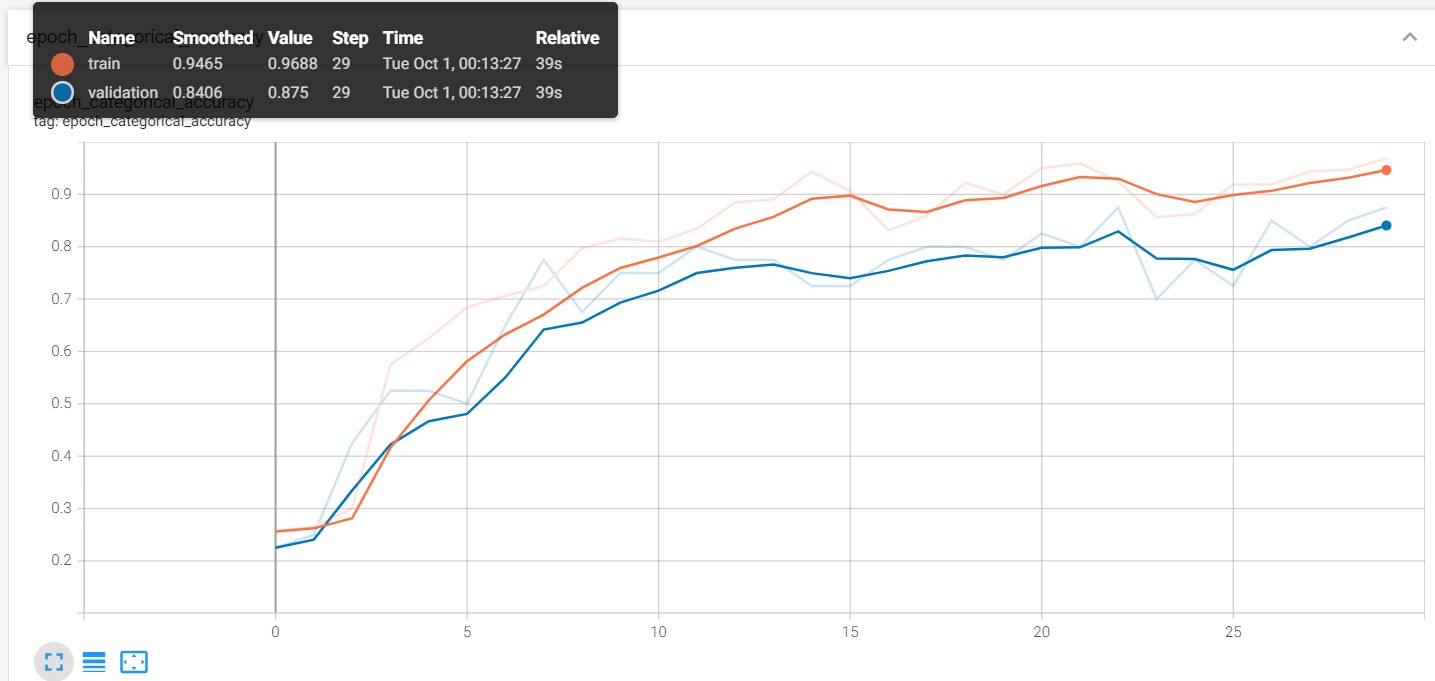
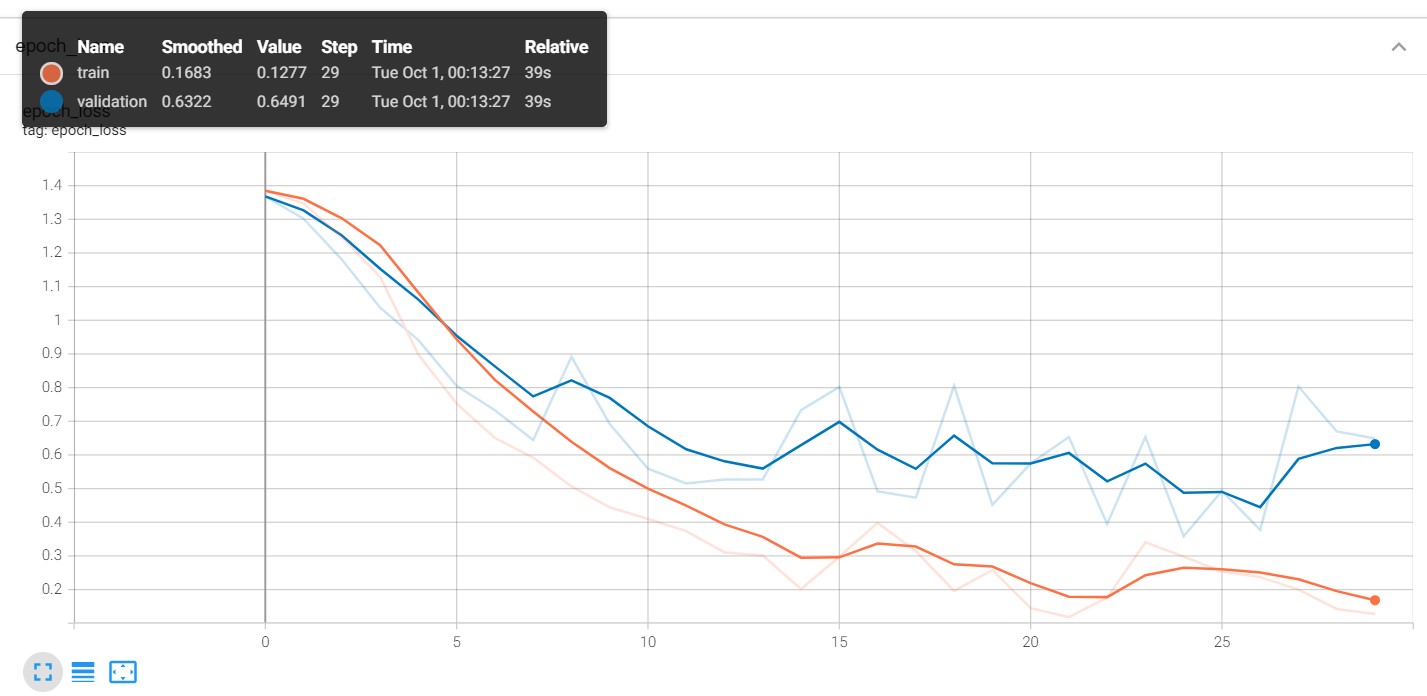
Results:
- Test Accuracy: 97.5%
- Test Loss: Minimal (mention the exact figure from your results).
Key Challenges:
Challenges Faced:
- Data Variability: Difficulty in ensuring consistent hand gestures across different lighting conditions and angles.
- Overfitting: Tackling overfitting with data augmentation.
- Real-Time Performance: Balancing accuracy and speed for real-time recognition.
Achievements and Future Work
Achievements:
- Achieved a 97.5% test accuracy on the limited dataset.
- Developed a pipeline for real-time recognition using webcam input.
- Custom Dataset: Collected custom Auslan alphabet gestures to train the model.
Ongoing Development and Future Work:
- Extend to Sentences: Plan to extend the system from recognizing individual letters to full Auslan sentences.
- Improve Generalization: Focus on improving the model’s robustness to different hand sizes, skin tones, and lighting conditions.
- Mobile Deployment: Explore deployment on mobile or edge devices for real-time accessibility solutions.
Conclusion
This project is a step towards enhancing communication accessibility for the deaf community. By translating Auslan fingerspelling gestures into text, it serves as a helpful tool for both deaf individuals and those learning sign language. In the future, the system can be expanded to recognize full sentences, further improving inclusivity and accessibility in education and public services.
Link of the project code on GitHub
Demo:
Thank you for you interest!
References:
Auslan(Australian Sign Language) Corpus. (2013, June 26). Research Data Australia. https://researchdata.edu.au/auslan-australian-sign-language-corpus/125009
Holden, E., Lee, G.,& Owens, R. (2005). Australian sign language recognition. Machine Visionand Applications, 16(5), 312–320. https://doi.org/10.1007/s00138-005-0003-1
Kadous, M. W. (1970).Machine Recognition of Auslan Signs Using PowerGloves: Towards Large-LexiconRecognition of Sign Language. ResearchGate. https://www.researchgate.net/publication/2828963_Machine_Recognition_of_Auslan_Signs_Using_PowerGloves_Towards_Large-Lexicon_Recognition_of_Sign_Language sca https://doi.org/10.1016/j.eswa.2022.118993
Rioux-Maldague, L.,& Giguere, P. (2014). Sign Language Fingerspelling Classification fromDepth and Color Images Using a Deep Belief Network. Ieeexplore. https://doi.org/10.1109/crv.2014.20
Shen, X., Yuan, S.,Sheng, H., Du, H., & Yu, X. (n.d.). Auslan-Daily: Australian Sign LanguageTranslation for Daily Communication and News. OpenReview. https://openreview.net/forum?id=g5v3Ig6WVq
Two-way Auslan:Automatic Machine Translation of Australian Sign Language. (n.d.). TheAustralian National University. https://researchportalplus.anu.edu.au/en/projects/two-way-auslan-automatic-machine-translation-of-australian-sign-l/
Willoughby, L., Smith,R. T., & Johnston, T. (2024). The GeSCA repository: Gesture and Sign Corpusof Australia. Australian Journal of Linguistics, 1–18. https://doi.org/10.1080/07268602.2024.2380672